한 번쯤은 들어봤을 법한 '크롤링'에 대해서 알아봄과 동시에
직접 해보는 것을 이번 글에서 다뤄보겠다.
크롤링(Crawling)이란?

네이버에 크롤링을 검색하면 IT용어사전에 나와 있는 정의이다.
또 다른 정의로는 아래에 나와 있다.
크롤링이란
'소프트웨어 따위가 웹을 돌아다니며 유용한 정보를 찾아 특정 데이터베이스로 수집해 오는 작업'

크롤링은 어디에서 사용되는 것일까?
웹 크롤링은 HTML 기반의 태그들로 되어 있는 것들을 가져올 수가 있다. 웹 사이트에 있는
이미지, 글, 문서 등이 있는데 가져올 수 있는 종류와 양이 많다.
자동으로 방대한 데이터를 수집할 수 있는 크롤링의 장점을 활용한다면
요즘 인기를 얻고 있는 AI 챗봇이나, 빅데이터 관련 분야에 활용을 할 수 있다.
이외에도 주식, 암호화폐 등 거래소에서 시세 정보를 모니터링 할 때,
쇼핑몰 상품 정보나 고객 데이터를 수집할 때,
도서관이나 서점에서 책을 찾는 시스템을 개발할 때 등 여러 분야에서 활용한다.
그럼 '파이썬(Python)'을 사용해 위에 본 정의 그대로, 웹에 있는 정보를 찾아
데이터베이스로 수집해 오는 작업인 '크롤링'을 간단하게 살펴보도록 하겠다.
우선, 파이썬 크롤링에 사용되는
bs4(beautifulsoup4)라는 파이썬 패키지를 설치해야 한다.
패키지 설치에 대한 설명은 아래 글에 자세히 나와 있으니,
이번 글에서는 간단히 설명하겠다.
파이참(PyCharm) 패키지 설치하기/ 파이참 패키지 설치 시 pip 오류 완벽 해결법/ 파이썬 가상환경이
파이썬은 라이브러리가 방대한 것으로 잘 알려져있다. 라이브러리(library)란? 네이버에 '라이브러리'를 검색했을 때 볼 수 있는 정의이다. 라이브러리란, 컴퓨터 프로그램에서 자주 사용되는 부
parkjh7764.tistory.com
패키지 설치에 대한 글을 보았다면 아래 창이 무엇을 의미하는지 알 것이다.
패키지를 검색하고 다운로드 받을 수 있는 창이다.
검색 창에 'bs4'를 검색해주고,
왼쪽 아래 install Package를 눌러 다운로드 받아준다.

다운로드가 완료되었다면, bs4 패키지를 사용해볼 것이다.
bs4 (BeautifulSoup) 패키지는 무엇인가?
BeautifulSoup 라이브러리는 웹 크롤링을 할 때 가장 중요하고 가장 많이 사용되는
라이브러리 중 하나이다. 웹에서 데이터를 가져올 때 번거로운 작업을 bs4를 사용하면
아주 간단하게 해결할 수 있다. HTML 파일을 쉽게 파싱(parsing)할 수 있다.
bs4 패키지를 활용해 네이버 영화 순위 웹스크래핑(크롤링) 해보기
bs4 패키지를 사용하기 위한 기본 골격이 있다.
구글에 'bs4 패키지 세팅' 등을 검색을 해서 찾아볼 수도 있겠지만
사용할 기본 골격은 아래에 코드로 남겨 놓겠다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
코드를 보면 조금 복잡한 부분이 있는데, 구글에 검색을 해보자.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}headers 부분은 사용자 에이전트 요청 헤더이다.
아래 영어로 된 정의를 해석하면,
사용자 에이전트 요청 헤더는 서버와 네트워크 피어가 요청하는 응용 프로그램, 운용체제, 또는
버전을 식별할 수 있는 특성 문자열이다.
추론을 해보면, 네트워크에게 우리가 크롤링을 하려는 크롤러라는 정보를 알려주는 코드인 것이다!
해당 코드에는 윈도우, 크롬, 사파리 등의 에이전트 UA 문자열이다.

그리고 기본 골격의 코드를 잘 보면 requests 라이브러리도 사용하고 있음을 볼 수 있다.
requests와 beautifulsoup 패키지 2개를 사용하는데,
그 이유가 크롤링과 관련되어 있다.
우선 requests 패키지로
브라우저를 켜지 않고도 requests 요청으로 코드를 가져오는 것.
그리고 beautifulsoup 패키지를 사용해서
요청해서 가져온 html 중에서 원하는 정보만을 솎아내는 것.
이 2가지가 크롤링을 할 때 기술적으로 중요하다.
위에 작성한 bs4에 대한 기본 틀을 가져와서
print(soup)를 사용해 soup에 어떤 데이터가 들어가 있는지 출력해보자.
requests.get("url")에 이미 url을 작성해놓았기 때문에, 그대로 사용해도 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup)

무언가 네이버에 관련된 것 같고, 평점과 미등록작 리스트, 관람하신 작품에 평점이란
단어를 보면 네이버에 드라마나 영화에 평점을 매기는 웹 사이트의 데이터인 것을 추론할 수 있다.
맞다.
우리가 지금 requests.get( )을 사용해 가져온 것은 아래의 주소의 소스코드이다.
네이버에 있는 영화들의 랭킹을 보여주는 웹 사이트의
소스코드를 가져온 것이다.
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com
위 링크로 들어가 마우스 오른쪽 버튼을 클릭해 '검사'를 눌러보자.

그러면 해당 웹 사이트의 '소스코드'를 볼 수 있다.
소스코드 부분을 클릭하고 ctrl + F 키를 눌러 '관람하신'을 찾아보자.
그러면 아까 우리가 soup를 출력해서 얻은 결과 값과 같다는 것을 확인할 수 있다.
그렇다!!! 그러면 soup 변수에 해당 웹 사이트 소스코드 전부를 넣은 것이다.

그럼 다시 돌아가 소스코드에 대해 설명을 좀 더 하겠다.
headers는 코드 단에서 요청을 했을 때 기본적인 요청은 막아둔 웹 사이트들이 많다.
그래서 내가 브라우저에서 엔터 친 것 마냥 효과를 내어주는 것이다.
headers = headers
그렇게 URL에 들어가 데이터를 요청에 받아오면
그것을 솎아내기 좋은 형태로 soup 변수에 받아오는 것이다.
BeautifulSoup의 사용 방법은 크게 2가지가 있다.
select_one과 그냥 select가 있다.
select_one은 이름에서 알 수 있듯이 하나만 나오고
select는 여러 개 리스트가 나온다.
그럼 바로 사용해보자.
BeautifulSoup .select_one 사용해보기



선택자를 복사하는데,
선택자는 타고 타고 들어가서 얘가 어디에 있는 지 알려주는 것이다.
그대로 복사해서 soup.select_one("")에 붙여넣기를 해준다.
그리고 title 변수를 클릭해주게 되면
우리가 아까 '보헤미안 랩소디' 이름을 셀렉터로 가져온 것이
그대로 결과 값으로 출력이 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one("#old_content > table > tbody > tr:nth-child(13) > td.title > div > a")
print(title)
그런데 결과 값에서 복잡해보이는 태그가 아니라
'보헤미안 랩소디'만 가지고 오고 싶다면 코드만 조금 변경해주면 된다.
바로 title.text로 바꿔주면 태그는 빼고 제목만 가져오게 된다.
print(title.text)
그리고 만약 태그에 대한 속성 값을 활용하기 위해
속성 값만을 가져오고자 한다면 아래와 같이 입력한다.
그러면 <a href = ""> 태그에서 속성 값에 해당하는 " " 큰 따옴표 부분을 가져온다.
print(title["href"])
select_one을 살펴보았는데 이것은 하나의 셀렉터만 가져올 때 사용한다.
우리가 하고자 하는 것은 영화 순위 여러 개를 가져와야 하기 때문에
하나가 아니다.
그럴 때는 select를 사용한다.
select를 사용해보자.
그 전에 html 구조에 대한 조금의 이해가 필요하다.
다시 웹 브라우저의 '검사'를 클릭해 영화 랭킹이
어떤 html 구조를 가지고 있는 지를 파악해보자.
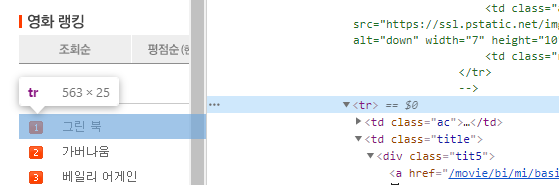

여기서 오른쪽에 있는 html 태그를 클릭해보며
어떤 요소들을 가르키는지를 본다. <tr> 태그가 우리가 원하는
순위 부분을 가져오는 것 같다.
그러면 ▼ 버튼을 눌러 닫아서 큰 틀을 보자.
아래 사진을 보면<tr> 태그가 여러개가 있다.
클릭한 <tr> 태그까지가 '10순위 터미네이터2: 오리지널'에 해당한다.
그러면 우리가 순위에 대한 소스코드를 가져오기 위해서
해당 <tr> 태그 부분에 대한 셀렉터를 복사하면 될 것같다!


아래와 같이 Copy -> Copy selector 을 해서 셀렉터를 가져온다.
그러고 복사한 것을 코드 편집기에 붙여넣기 해보자.

<tr> 태그들을 복사해서 붙여넣어보면 아래와 같은 셀렉터가 나올 것이다.
그런데 잘 보면, 규칙을 발견할 수가 있다.
tr : nth-childe( ) 부분
괄호 안 숫자만 변경되는 것을 알 수 있다.
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)
#old_content > table > tbody > tr:nth-child(4)
#old_content > table > tbody > tr:nth-child(5)
#old_content > table > tbody > tr:nth-child(6)
#old_content > table > tbody > tr:nth-child(7)그렇다면 조금만 더 생각을 해보면...
귀찮게 하나 하나 셀렉터를 복사해서 붙여넣기 하는 번거로운 일을 하지 않을 수 있지 않을까...
공통적인 tr 부분까지만 가져온다면
우리가 가져오고자 하는 <tr> 부분의 영화 순위는 다 가져올 수 있음을 파악할 수 있다.
#old_content > table > tbody > tr그럼 가져온 셀렉터를 활용해 select를 사용해보자.
여기서 참고해야할 것은 select_one과 다르게 select는
출력 값이 '리스트'의 형태로 나온다는 것이다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select("#old_content > table > tbody > tr")
for tr in trs:
print(tr)결과 값에서 볼 수 있듯이 1순위인 그린 북부터 시작해서

순위 마지막인 50위 '울지마 톤즈'까지 리스트의 형태로 가지고 오는 것을 확인할 수 있다.

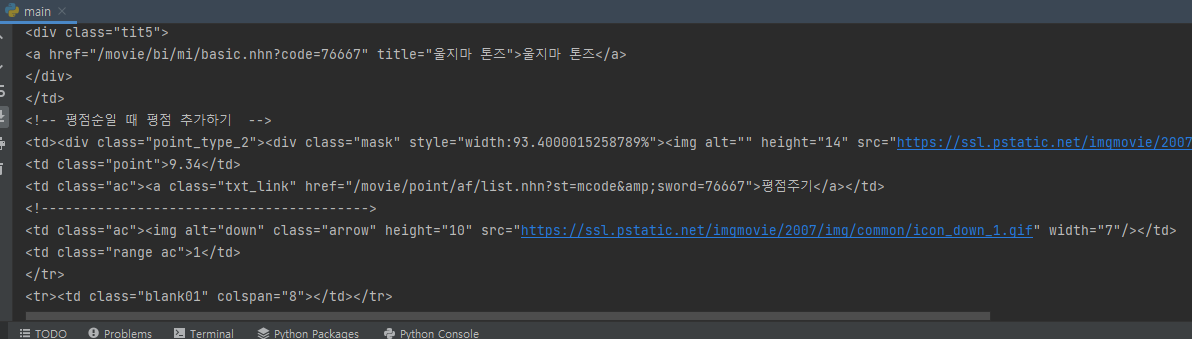
우리가 원하는 것은 영화 순위들의 모든 태그들과 데이터가 아니라
영화 제목이나 평점, 순위 등에 대한 데이터만 사용하고 싶다.
그렇게 해보자.
그럼 다시 그린북 'title' 즉, 제목에 대한 소스코드를 보고
셀렉트를 복사해 와 붙여넣게 되면 아래와 같다.

뭔가 규칙이 보이지 않는가?
아까는 #old_content > table > tbody > tr:nth-child(2)
여기 부분을 확인할 수 있었다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a그러면 타이틀 제목에 해당되는 부분을 가져오기 위해서는
td.title > div > a 를 사용하면 되는 것을 파악할 수 있다.
자 그러면 영화 제목만 가져와보자.
select와 select_one을 사용해 영화 제목 크롤링하기
우선 코드는 아래와 같다.
select(" ")를 사용해 tr 부분까지의 순위에 있는 영화에 대한 전체 소스코드를 가져오고,
for 반복문 안에 select_one(" ")을 사용해 영화 타이틀만 가져오는 것이다.
여러 개가 아니라 영화 제목만 가져오면 되기 때문에 select_one( )을 사용하였다.
select로 tr까지 찾은 곳에서 select_one으로 td.title > div > a 까지 또 찾아준다고 보면 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select("#old_content > table > tbody > tr")
for tr in trs:
a_tag = tr.select_one("td.title > div > a")
print(a_tag)
※ 가져오려는 하려는 웹의 소스코드들은 사이트마다 다 다르기 때문에
사이트에 코드에 맞게 셀렉터를 복사해와 사용해야 한다. ※
위의 결과 값을 보게 되면 'None' 값이 섞여 있는 것을 확인할 수 있다.
브라우저의 '검사' 창에서 확인해보면 순위들 마다 구분을 지어주는 '줄'을 나타내는 것이다.

그럼 만약에 위에서 title.text로
태그들을 빼고 영화 제목만 가져오고 싶다고 해서 title.text를 사용했을 때,
None 값 때문에 오류가 날 것이다.
그러면 None에 해당되는 부분을 조건문으로 없애주면 되는 것이다.
for 반복문 안에 if 조건문을 넣어주자.
for tr in trs:
title_a = tr.select_one("td.title > div > a")
if title_a is not None:
print(title_a.text)그럼 아래와 같이 영화 이름만을 가져올 수가 있게 된다.

조금 더 나아가보자.
영화 이름만이 아니라, 네이버 영화 순위에서
순위, 영화 이름, 평점을 크롤링해보자.
위에 내용을 이해했다면, 스스로 할 수 있을 것이다.
코드만 남겨놓겠다.
아래 코드에서 순위는 웹에서 가져온 것이 아니라,
ranking 변수를 두어 None 값일 때를 제외하고 순서대로 번호를 매긴 것이다.
이렇게 하지 않아도 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select("#old_content > table > tbody > tr")
ranking = 1;
for movie in movies:
movie_name = movie.select_one("td.title > div > a")
movie_point = movie.select_one("td.point")
if movie_name is not None:
print(ranking, movie_name.text, movie_point.text)
ranking = ranking + 1

위에 코드처럼 ranking 변수를 두지 않고 크롤링해서 랭킹 순위까지 가지고 와보자.
여기서 "alt" 속성 부분이 순위를 의미하기 때문에 alt 속성 값을 가져와야 한다.
위에서 다룬 속성 값만 가져오는 방법을 쓰면 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select("#old_content > table > tbody > tr")
for movie in movies:
movie_name = movie.select_one("td.title > div > a")
movie_point = movie.select_one("td.point")
if movie_name is not None:
ranking = movie.select_one("td:nth-child(1) > img")["alt"]
print(ranking, movie_name.text, movie_point.text)




댓글