driver.find_element_by_xpath('//*[@id="main-area"]/div[7]/a[2]') #xpath 로 접근
driver.find_element_by_class_name('some_class_name') #class 속성으로 접근
driver.find_element_by_id('html_id') #id 속성으로 접근
driver.find_element_by_link_text('회원가입') #링크가 달려 있는 텍스트로 접근
driver.find_element_by_css_selector('#css>div.selector') #css 셀렉터로 접근
driver.find_element_by_name('html_name') #name 속성으로 접근
driver.find_element_by_partial_link_text('가입') #링크 엘레먼트에 텍스트 일부만 적어 접근
driver.find_element_by_tag_name('h1') #태그 이름으로 접근
그러나selenium 4.3.0버전부터위와 같이 접근하는 방식의 메소드가 변경되었다.
find_element( )를 사용해야 한다.
4.3.0 버전보다 높은 버전에서 위와 같은 driver.find_element_by_id 와 같은 메서드를 사용하면
아래와 같은 오류가 발생한다.
Selenium - Python - AttributeError:'WebDriver'
변경된 element 접근 방식
from selenium.webdriver.common.by import By
셀레니움 버전 3 메서드
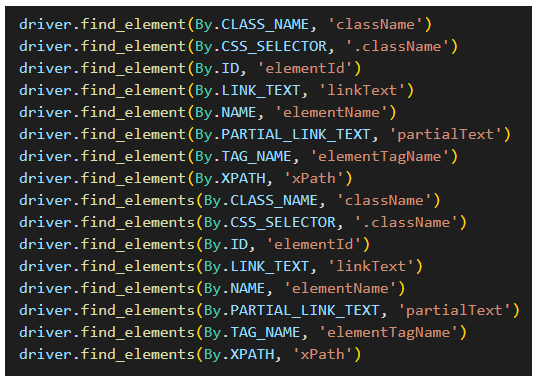
셀레니움 버전 4 메서드
셀레니움을 사용해 네이버 검색어 입력 후 검색 버튼까지 클릭하는 예제
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
craw_keyword = input('크롤링할 키워드를 입력해주세요 : ')
#크롬 드라이버로 웹 브라우저 실행
path = "C:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get("https://www.naver.com/")
time.sleep(2)
#검색창을 찾아 검색어 입력
driver.find_element(By.ID,'query').click()
element = driver.find_element(By.ID, 'query')
element.send_keys(craw_keyword)
#검색 버튼을 눌러 실행
driver.find_element(By.ID,'search_btn').click()
코드 설명
from bs4 import BeautifulSoup
from selenium import webdriver
import time
craw_keyword = input('크롤링할 키워드를 입력해주세요 : ')
- bs4와 selenium 모듈을 import 한다.
- time 모듈은 페이지가 전부 열릴 때까지 기다려주는 명령을 실행하기 위해 import 한다.
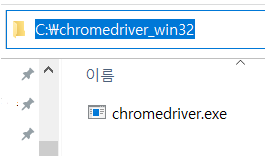
- 1번줄 : path 변수에 chromedriver.exe 파일이 있는 경로를 저장한다.
- 1번줄 : 나는 chromedriver.exe 파일을 c드라이브에 chromedriver_win32 폴더에 넣어놓았다. -> 아래처럼 해당 폴더에 들어가 주소를 복사해서 사용한다.
- 2번줄 : webdriver.Chrome(path)로 2번 줄에 있는 파일로 인터넷을 사용해라는 것을 지정한다.
- 4번줄 : driver.get("URL주소") 명령어로 주어진 URL 주소를 웹 페이지에 oepn 한다.
- 5번줄 : time.sleep(2)는 해당 페이지가 전부 로딩될 때까지 2초 기다리게 하는 명령어이다.
#검색창을 찾아 검색어 입력
driver.find_element(By.ID,'query').click()
element = driver.find_element(By.ID, 'query')
element.send_keys(craw_keyword)
#검색 버튼을 눌러 실행
driver.find_element(By.ID,'search_btn').click()
- 2번줄 : driver.find_element(By.ID,'query').click()는 selenium에게 현재 보이는 창에서 id 값이 headerSearchKeyword 라는 것을 찾아서 클릭하라는 명령어이다.
- 4번줄 : id가 'query'인 element를 찾아 변수에 넣는다.
- 6번줄 : send_keys 부분에서 사용자로부터 입력받은 키워드를 검색어에 입력한다.





댓글